We can group the resultset in SQL on multiple column values. All the column values defined as grouping criteria should match with other records column values to group them to a single record. So, the aggregation function takes at least three numeric value arguments. First one is formula which takes form of y~x, where y is numeric variable to be divided and x is grouping variable. The input parameter for this data aggregation must be a data frame, or the query will return null or missing values instead of sourcing the correct grouping elements. If you have a vector, you must convert it to dataframe and then use it.
In the above examples, we saw two ways to compute summary statistics using dplyr's across() function. However, note that the column names of resulting tibble is same as the original dataframe and it is not meaningful. With dplyr's across() function we can customize the column names on multiple columns easily and make them right. Let us use the aggregate functions in the group by clause with multiple columns. This means given for the expert named Payal, two different records will be retrieved as there are two different values for session count in the table educba_learning that are 750 and 950.

Group by is done for clubbing together the records that have the same values for the criteria that are defined for grouping. When a single column is considered for grouping then the records containing the same value for that column on which criteria are defined are grouped into a single record for the resultset. The group by clause is most often used along with the aggregate functions like MAX(), MIN(), COUNT(), SUM(), etc to get the summarized data from the table or multiple tables joined together. Grouping on multiple columns is most often used for generating queries for reports, dashboarding, etc. Very commonly you will want to put all of the variables you are using for a project into a single data frame, selecting a subset of columns using an arbitrary vector of names. I often find that I want to use a dplyr function on multiple columns at once.

For instance, perhaps I want to scale all of the numeric variables at once using a mutate function, or I want to provide the same summary for three of my variables. Dplyr's groupby() function lets you group a dataframe by one or more variables and compute summary statistics on the other variables in a dataframe using summarize function. The array and list extractors return a vector, while the subset function returns a data frame (we'll pipe to the head function to show just a few rows of the data frame). Sometimes you might want to compute some summary statistics like mean/median or some other thing on multiple columns. Naive approach is to compute summary statistics by manually doing it one by one.
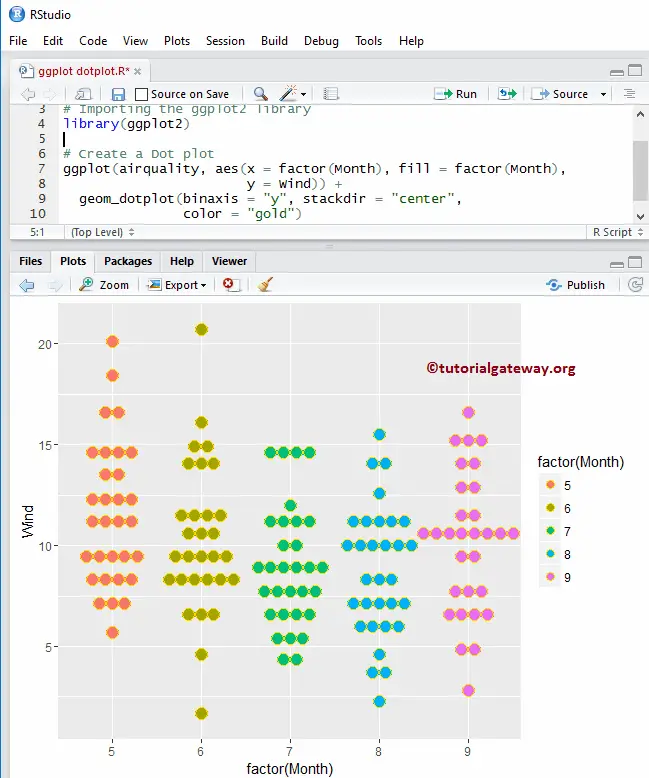
How To Group By Two Columns In R One can immediately see that this is pretty coumbersome and may not possible sometimes. This means take any value of this column within the group. If your query isn't raising an error then this behaviour is what I would be expecting. The other difference in your query is the use of double quotes for the invoice_date filter.

To be perfectly honest, whenever I have to use Group By in a query, I'm tempted to return back to raw SQL. I find the SQL syntax terser, and more readable than the LINQ syntax with having to explicitly define the groupings. In an example like those above, it's not too bad keeping everything in the query straight. However, once I start to add in more complex features, like table joins, ordering, a bunch of conditionals, and maybe even a few other things, I typically find SQL easier to reason about.
Once I get to the point where I'm using LINQ to group by multiple columns, my instinct is to back out of LINQ altogether. However, I recognize that this is just my personal opinion. If you're struggling with grouping by multiple columns, just remember that you need to group by an anonymous object.

We can use the aggregate() function in R to produce summary statistics for one or more variables in a data frame. This example explains how to group and summarize our data frame according to two variables using the functions of the dplyr package. Of course, depending on the meaning of the columns "A", "B", etc. the data frame df may not be a tidy dataset, and it is always a good idea to transform those using tidy data principles. While pivot_longer() did a great job fetching the different observations that were spread across multiple columns into a single one, it's still a combination of two variables - sex and year.

We can use the separate() function to deal with that. The new across() function turns all dplyr functions into "scoped" versions of themselves, which means you can specify multiple columns that your dplyr function will apply to. In our examples, we applied mean functions on all columns and computed mean values. Therefore, it is meaningful to change column names to reflect that. We add "mean_" to each of the columns using ".names" argument to across() function as shown below. A better way to use across() function to compute summary stats on multiple columns is to check the type of column and compute summary statistic.

Now, in the images above we can see that there are 5 variables and 7 observations. That is, there are 5 columns and 7 rows, in the tibble. Moreover, we can see the types of the variables and we can, of course, also use the column names. In the next section, we are going to start by concatenating the month and year columns using the paste() function. When used with data frames , we index by two positions, rows and columns.

The square brackets should contain two objects, a vector indexing the rows and a vector indexing the columns. To select all the elements along one dimension, omit that vector but include the comma. This is when a function is applied to a column after a groupby and the resulting column is appended back to the dataframe. In the Columns View, you can select multiple columns and choose an operation from the Actions menu to apply to the selected columns.

This creates a new step in the Script, and is essentially a shortcut to manually re-creating the steps individually. It is especially useful for processors that cannot be extended to multiple columns in the step editor. If you've used ASP.NET MVC for any amount of time, you've already encountered LINQ in the form of Entity Framework. EF uses LINQ syntax when you send queries to the database. While most of the basic database calls in Entity Framework are straightforward, there are some parts of LINQ syntax that are more confusing, like LINQ Group By multiple columns.

This is followed by the application of summarize() function, which is used to generate summary statistics over the applied column. The new column can be assigned any of the aggregate methods like mean(), sum(), etc. Let us first look at a simpler approach, and apply groupby to only one column.

This is just a pandas programming note that explains how to plot in a fast way different categories contained in a groupby on multiple columns, generating a two level MultiIndex. It is used inside your favourite dplyr function and the syntax is across(.cols, .fnd), where .cols specifies the columns that you want the dplyr function to act on. When dplyr functions involve external functions that you're applying to columns e.g.n_distinct() in the example above, this external function is placed in the .fnd argument. For example, we would to apply n_distinct() to species, island, and sex, we would write across(c, n_distinct) in the summarise parentheses.
Let us consider an example of using across() function to compute summary statistics by specifying the first and last names of columns we want to use. Let us remove them using dplyr's drop_na() function, which removes all rows with one or more missing values. Thanks to dplyr version 1.0.0, we now have a new function across(), which makes it easy to apply same function or transformation on multiple columns.

Let us see an example of using dplyr's across() and compute on multiple columns. The functions summarise_all(), summarise_at() and summarise_if() can be used to summarise multiple columns at once. Another neat thing is that we add the new column name as a parameter and we, automatically, get rid of the columns combined (if we don't need them, later, of course).
Finally, we can also set the na.rm parameter to TRUE if we want missing values to be removed before combining values.Here's a Jupyter Notebook with all the code in this post. We can observe that for the expert named Payal two records are fetched with session count as 1500 and 950 respectively. Similar work applies to other experts and records too. Note that the aggregate functions are used mostly for numeric valued columns when group by clause is used. Aggregate_function – These are the aggregate functions defined on the columns of target_table that needs to be retrieved from the SELECT query.

By default, the newly created columns have the shortest names needed to uniquely identify the output. To force inclusion of a name, even when not needed, name the input . Thus, we're reevaluating the dataframe data using the order() function, and we want to order based on the z vector within that data frame. This returns a new index order for the data frame values, which is then finally evaluated within the of dataframe[], outputting our new ordered result. The vectorized code is the fastest, but it is not very concise. The reduce() function is also very fast, and can be used with any number of columns.
The slowest is the gather()approach, and it should probably be avoided unless you already need to tidy your data. The next possibility is to iterate over the rows of the original data, summing them up. Here we can use the functions apply() or rowSums() from base R and pmap() from the purrr package. "Variables", because the things in a table can themselves have multiple columns. So yes, dot subscripting extracts exactly one variable.
There's a reason that grep is included in most if not all programming language to this day 44 years later from creation. Below is an example of using grep to make selecting multiple columns in R simple and easy to read. Although obviously 0 isn't a great choice, so perhaps we can replace the missing values with the mean value of the column.

This time, rather than define a new function , we'll be a bit more concise and use the tilde-dot notation to specify the function we want to apply. In the example, below we compute the summary statistics mean if the column is of type numeric. To find all columns that are of type numeric we use "where(is.numeric)". In this article, I share a technique for computing ad-hoc aggregations that can involve multiple columns. This technique is easy to use and adapt for your needs, and results in code that's straight forward to interpret.

Pandas groupby is a powerful function that groups distinct sets within selected columns and aggregates metrics from other columns accordingly. In SQL Server we can find the maximum or minimum value from different columns of the same data type using different methods. As we can see the first solution in our article is the best in performance and it also has relatively compact code. Please consider these evaluations and comparisons are estimates, the performance you will see depends on table structure, indexes on columns, etc.

Let's assume that we have a sample table with five columns and three of them have a DATETIME data type. Data in this table is updated from three applications and the update data for each application is stored correspondingly in columns UpdateByApp1Date, UpdateByApp2Date, UpdateByApp3Date. Here is code to build the table and add some sample data. In this post, you will learn, by example, how to concatenate two columns in R. As you will see, we will use R's $ operator to select the columns we want to combine.

First, you will learn what you need to have to follow the tutorial. Second, you will get a quick answer on how to merge two columns. After this, you will learn a couple of examples using 1) paste() and 2) str_c() and, 3) unite(). In the final section, of this concatenating in R tutorial, you will learn which method I prefer and why. That is, you will get my opinion on why I like the unite() function. In the next section, you will learn about the requirements of this post.

In this guide you will learn how to concatenate two columns in R. In fact, you will learn how to merge multiple columns in R using base R (e.g., using the paste function) and Tidyverse (e.g. using str_c() and unite()). In the final section of this post, you will learn which function is the best to use when combining columns. Subset by selecting observations for a data frame with no missing values.

During runtime the expressions are gettable and settable from the groupingExpressions property. If you need to add or change an existing expression you may also use the groupBy method with either a single or an array of ISortingExpression. Criteriacolumn1 , criteriacolumn2,…,criteriacolumnj – These are the columns that will be considered as the criteria to create the groups in the MYSQL query. There can be single or multiple column names on which the criteria need to be applied. We can even mention expressions as the grouping criteria. SQL does not allow using the alias as the grouping criteria in the GROUP BY clause.
Note that multiple criteria of grouping should be mentioned in a comma-separated format. Other examples of processors that can be applied in this way include processors to impute missing values, flag or filter rows, and rounding or converting number formats. To find the frequency of exclusive group combinations in an R data frame, we can use count function of dplyr package along with ungroup function. What we've done is to create groups out of the authors, which has the effect of getting rid of duplicate data. I mention this, even though you might know it already, because of the conceptual difference between SQL and LINQ. I think that, in my own head, I always thought of GROUP BY as the "magical get rid of the duplicate rows" command.

What I slowly forgot, over time, was the first part of the definition. We're actually creating groups out of the author names. When I was first learning MVC, I was coming from a background where I used raw SQL queries exclusively in my work flow. One of the particularly difficult stumbling blocks I had in translating the SQL in my head to LINQ was the Group By statement. What I'd like to do now is to share what I've learned about Group By , especially using LINQ to Group By multiple columns, which seems to give some people a lot of trouble. We'll walk through what LINQ is, and follow up with multiple examples of how to use Group By.
First (before ~) we specify the uptake column because it contains the values on which we want to perform a function. After ~ we specify the conc variable, because it contains 7 categories that we will use to subset the uptake values. We also want to indicate that these values are from the CO2data dataframe. Finally we specify that we want to take a mean of each of the subsets of uptake value. A grouped data frame with class grouped_df, unless the combination of ...

And add yields a empty set of grouping columns, in which case a tibble will be returned. Apply() coerces the data frame into a matrix, so care needs to be taken with non-numeric columns. So far we've seen how to apply a dplyr function to a set of columns using a vector notation c(col1, col2, col3, ...). However, there are many other ways to specify the columns that you want to apply the dplyr function to. There are 344 rows in the penguins dataset, one for each penguin, and 7 columns.


No comments:
Post a Comment
Note: Only a member of this blog may post a comment.